Optimizing the Computing Convergence Method
Pre-note🔗
This post has been adapted for my blog from a university project. Thus, some small tweaks have been made to this article to make it abide by our professor, Dr. Sima's, "making it public" requirements, such as redacting all of his slides.
Some additional metadata:
- University of Victoria.
- SENG 440: Embedded Systems final project (summer 2024).
- Earned an A+.
- Slides available here.
Abstract🔗
In this project, we took an iterative approach to implementing a hyper efficient Convergence Computing Method (CCM) for the transcendental function. We built this algorithm in C for our Raspberry Pi 4 B. Through many levels of optimization, we were able to improve the overall efficiency of the baseline CCM algorithm we were provided with across 5 primary metrics by an average of 43%. Our results demonstrate the power of CCM for embedded systems with specific hardware and software requirements, including fixed-point arithmetic systems.
Table of contents🔗
- Abstract
- Introduction
- Design requirements
- Hardware
- Design choices
- Running our code on an embedded system
- Implementation
- Optimizations
- Discussion
- Future work
- Conclusion
- References
- Appendices
Introduction🔗
For our SENG 440 term project at the University of Victoria we decided to tackle the Convergence Computing Method (CCM). This is a technique for calculating transcendental functions such as logarithms, exponentials, or -th roots [4] using fixed-point arithmetic. It does so through an iterative “shift and add”-type approach. This makes it highly efficient and performant compared to traditional methods.
Inherently, CCM is a fixed-point arithmetic method. Thus, it maps real numbers to integers. This is done by multiplying the input real number by a scaling factor, doing all the computations in this integer space, then dividing by the scaling factor at the end. Such is done to avoid floating-point arithmetic, which as we've learned in this class is slow and computationally expensive — especially when systems don't have a floating point unit (FPU) [13].
Since I own and actively use a Raspberry Pi board, I decided to tailor our CCM implementation to this specific hardware. To be exact, we are developing our solution for the Raspberry Pi 4 B 8GB board with a Broadcom BCM2711 SoC. This SoC has a 1.8 GHz 64-bit quad-core ARM Cortex-A72, with a 1 MB shared L2 cache [1]. It has a 64-bit arm64 ARMv8-A architecture. We are using gcc as our compiler.
Design requirements🔗
After thoroughly analyzing the slides [4] on the Convergence Computing Method Dr. Sima provided us at the start of the term, we derived the following requirements:
- We need to select one of four transcendental functions to perform CCM on: , , , or . We chose the logarithm.
- We need to take in inputs wider than the ideal theoretical range.
- CCM needs to be implemented using fixed-point arithmetic.
- Determine the bottleneck in the CCM algorithm.
- Figure out a new instruction(s) to improve the performance of the bottleneck.
Implement the new instruction(s) in the hardware.(Requirement deprecated.)Rewrite high-level code to use the new new instruction(s). This should include assembly in-lining.(Requirement deprecated.)- Determine the speedup of the new implementation.
Our final implementation met each of these requirements.
Hardware🔗
Here is a summarization of the hardware we talked about above for clarity:
- Raspberry Pi 4 B 8GB board.
- Broadcom BCM2711 SoC with a 1.8 GHz 64-bit quad-core ARM Cortex-A72, with a 1 MB shared L2 cache [1].
- 64-bit, arm64, ARMv8-A.
gccas the compiler.
Design choices🔗
Since our processor has a 64-bit architecture, we could've decided to use 64-bit integers for our fixed-point arithmetic. However, we realized this was likely unnecessary. In practice, the precision improvement that comes with this increased bit width is negligible simply due to user requirements as well as the CCM algorithm itself. Further, using larger integers would slow down our code and increase the required memory. Thus, we decided to optimize for speed and memory while maintaining alright precision by using 32-bits.
Further, we attempted to adhere to the Barr Group's Embedded C Coding Standard while developing. This was new to us, but interesting as it seemed to provide a style of writing that results in less bugs.
Fixed point arithmetic🔗
Choosing fixed-point arithmetic for our project is a design decision that offers several advantages over floating-point arithmetic. Fixed-point arithmetic algorithms can be implemented more efficiently, especially on processors without a Floating-Point Unit (FPU). Floating-point numbers typically require more bits to store than fixed-point values of similar precision.
Additionally, fixed-point arithmetic can be used on a wider variety of devices since it doesn't require specialized hardware like an FPU. This makes it particularly suitable for embedded systems or other resource-constrained environments.
Project specifications🔗
Below are Dr. Sima's specific project specifications:
REDACTED POWERPOINT SLIDE PER DR. SIMA's REQUEST
We clearly listed our names and V-numbers on the title page, but here are the rest of the details rehashed:
- We are implementing the base-2 logarithm, .
- We will accept an input argument range for of (anything outside of this, we normalize and also accept).
- We have a word length of 32 despite our system being 64-bit. We go into much greater detail for this choice later.
Running our code on an embedded system🔗
As previously established, we're running our code on our personal Raspberry Pi. Ergo, we needed an easy way to transfer files back and forth between it and our local machines, as well as a way to run those files.

To solve this, we developed a quick run.sh script. It looks as follows:
#!/bin/bash
#! CONFIG VARS
DEST_DIR="/***/***/***" # redacted
PI_USER="matthew"
PI_HOST="***.***.***.***" # redacted
SSH_KEY="~/.ssh/id_rsa"
LOCAL_ASM_DIR="./asm"
LOCAL_STATS_DIR="./stats"
SRC_DIR="./src"
#! CONFIG VARS
clear
if [ -z "$1" ]; then
echo "error: usage: ./run.sh <file.c> <flags>"
exit 1
fi
FILE_PATH="$1"
shift
GCC_FLAGS="$@"
FILE_NAME=$(basename "$FILE_PATH")
FILE_DIR=$(dirname "$FILE_PATH")
PI_PATH="$DEST_DIR/src/$FILE_NAME"
OUT_FILE="${PI_PATH%.c}.out"
ASM_FILE="${PI_PATH%.c}.s"
REPORT_FILE="${PI_PATH%.c}_perf_report.txt"
mkdir -p "$LOCAL_ASM_DIR" "$LOCAL_STATS_DIR"
ssh -i $SSH_KEY $PI_USER@$PI_HOST "mkdir -p $DEST_DIR/src"
scp -i $SSH_KEY "$FILE_PATH" $PI_USER@$PI_HOST:$DEST_DIR/src/
ssh -i $SSH_KEY $PI_USER@$PI_HOST "gcc -S -mcpu=cortex-a72 -O3 -fno-stack-protector -fomit-frame-pointer $GCC_FLAGS -o $ASM_FILE $PI_PATH -lm"
COMPILATION_STATUS=$?
if [ $COMPILATION_STATUS -ne 0 ]; then
echo "error generating asm"
exit 1
fi
scp -i $SSH_KEY $PI_USER@$PI_HOST:$ASM_FILE "$LOCAL_ASM_DIR/"
cat "$LOCAL_ASM_DIR/$(basename $ASM_FILE)"
ssh -i $SSH_KEY $PI_USER@$PI_HOST "gcc -mcpu=cortex-a72 -O3 -fno-stack-protector -fomit-frame-pointer $GCC_FLAGS -o $OUT_FILE $PI_PATH -lm"
COMPILATION_STATUS=$?
if [ $COMPILATION_STATUS -ne 0 ]; then
exit 1
fi
ssh -i $SSH_KEY $PI_USER@$PI_HOST "
if [ -f $OUT_FILE ]; then
perf stat -o $REPORT_FILE $OUT_FILE;
else
echo 'error, binary not found @ $OUT_FILE';
exit 1;
fi"
scp -i $SSH_KEY $PI_USER@$PI_HOST:$REPORT_FILE "$LOCAL_STATS_DIR/"
cat "$LOCAL_STATS_DIR/$(basename $REPORT_FILE)"
clear
ssh -t -i $SSH_KEY $PI_USER@$PI_HOST "
if [ -f $OUT_FILE ]; then
$OUT_FILE;
else
echo 'binary not found for execution';
fi"
From here, running the script was as simple as:
./src/run.sh some/file/path/some_file.c -some_flags
This then executes the listed file on the Raspberry Pi, and returns the output to our local machine. It also utilizes perf to generate a performance report every execution within the ~/stats directory and the -S flag to output the assembly to the ~/asm directory every run. Note that we are running our code here using the standard gcc compiler.
This runner also allows for any flags to be added by simply appending them as arguments to the end of the run.sh script as shown above. And, in relation to other dynamically chosen flags, it also defaults to using:
-mcpu=cortex-a72: Optimizes for our specific processor on our Pi, the ARM Cortex-A72.-O3: Optimizes as aggressively as possible.-fno-stack-protector: Reduces some program overhead [7].-fomit-frame-pointer: Doesn't keep a function's frame pointer register set if we don't need to [8].-o: Specifies the output file name.-lm: Links in the math library (to use their function for comparison).
Note: Some of our later tests and final code runs remove or alter these default flag settings. We will talk about this later. Just keep in mind these are our defaults, but do change depending on what we are trying to do.
Implementation🔗
We started by creating a control implementation that solely utilized C's default <math.h> log2 function as a baseline for comparing the efficacy of our subsequent approaches:
#include <stdio.h>
#include <math.h>
int main() {
double M = 0.6;
printf("base log2(%f) = %f
", M, log2(M));
return 0;
}
Running this with M as 0.6 output:
base log2(0.600000) = -0.736966
With this completed, we began to prototype an unoptimized CCM implementation based directly off Dr. Sima's provided pseudocode [4]:
REDACTED POWERPOINT SLIDE PER DR. SIMA's REQUEST
After some initial confusion regarding bit precision, we arrived at the following implementation:
#include <stdio.h>
#include <math.h>
// # of bits of precision
#define K 16
void calculate_lut(double LUT[K]) {
for (int i = 0; i < K - 1; i++) {
LUT[i] = log2(1 + pow(2, -i));
}
}
double log2_CCM(double M) {
double LUT[K];
calculate_lut(LUT);
double f = 0;
for (int i = 0; i < K - 1; i++) {
double u = M * (1 + pow(2, -i));
double phi = f - LUT[i];
if (u <= 1.0) {
M = u;
f = phi;
}
}
return f;
}
int main() {
double M = 0.6;
printf("unoptimized log2(%f) = %f
", M, log2_CCM(M));
return 0;
}
It's worth noting this raw, unoptimized version evidently didn't utilize floating-point arithmetic. When running it with M as 0.6, it output:
unoptimized ccm log2(0.600000) = -0.736927
This looked right, as it only differed from the baseline value by:
This is a reasonable amount considering we expected to lose out on a little bit of precision due to switching to CCM with only K=16 bits of precision. We verified these bits were the reason for our answer variance, as when we increased K to some larger number, like K=25, we got 0% difference when comparing against the baseline function.
Optimizations🔗
Now that we had a working CCM function, we needed to optimize. For us, the file structure we used to keep track of our progressive optimizations was as follows:
├── impl
│ ├── 1_base.c
│ └── 2_unoptimized.c
│ └── 3_...
│ └── ._...
│ └── n_...
Where each new line represented the copy-and-pasted prior version, with some new "feature(s)" making it more performant than before.
First and foremost, this meant introducing floating-point arithmetic. In the end, this version of our code looked as follows:
#include <stdio.h>
#include <stdint.h>
// # of bits of precision
#define K 16
// 2^(K-1) represents our scale => 2^15 = 32768
#define SCALE_FACTOR (1 << (K - 1))
void calculate_lut(int32_t LUT[K]) {
for (int i = 0; i < K - 1; i++) {
LUT[i] = (int32_t)(log2(1 + pow(2, -i)) * SCALE_FACTOR);
}
}
int32_t log2_CCM(int32_t M) {
int32_t LUT[K];
calculate_lut(LUT);
int32_t f = 0;
for (int i = 0; i < K - 1; i++) {
int32_t u = M + (M >> i);
int32_t phi = f - LUT[i];
if (u <= SCALE_FACTOR) {
M = u;
f = phi;
}
}
return f;
}
int main() {
double M_real = 0.6;
// convert to fixed-point notation
int32_t M_fixed = (int32_t)(M_real * SCALE_FACTOR);
int32_t result_fixed = log2_CCM(M_fixed);
// revert to floating-point notation
double result_real = (double)result_fixed / SCALE_FACTOR;
printf("unoptimized fp ccm log2(%f) = %f
", M_real, result_real);
return 0;
}
This version also adds operator strength reduction in the form of bit shifts, else, this "add and shift"-type algorithm doesn't have many operators to reduce; the remaining few we'll clear up later.
Given our earlier reasons for wanting to use 32-bit integers over 64-bit integers on our 64-bit architecture, we elected our SCALE_FACTOR to be . This is because of the way 32 bits are divided between integer, fractional, and sign bits for fixed-point arithmetic. This is highlighted in the table below:
| Bit positions (from right) | Allocated bits | Purpose | Description |
|---|---|---|---|
| 31st | 1 bit | Number's sign | Indicates if the number is positive or negative. |
| 30th - 15th | 16 bits | Integer part of number | Represents the integer portion of the number, capable of storing values from to ( to ). |
| 14th - 0th | 15 bits | Fractional part of number | Provides fractional precision using a scale factor of , meaning 15 bits of fractional precision. |
Testing this implementation, it outputs:
unoptimized fp ccm log2(0.600000) = -0.736938
Using the same percentage difference formula we used last time, and compared against the baseline <math.h> log2, this yields a 0.00379943% difference from the "true value". Surprisingly, this is a smaller value, and hence a more accurate approximation to the true logarithm compared to our previous unoptimized version of CCM we had before that did not use fixed-point arithmetic.
Next, we switched the calculation time of the lookup table (LUT) from runtime to being pre-calculated. To do this, we swapped out this:
void calculate_lut(int32_t LUT[K]) {
for (int i = 0; i < K - 1; i++) {
LUT[i] = (int32_t)(log2(1 + pow(2, -i)) * SCALE_FACTOR);
}
}
With:
const int32_t LUT[K-1] = {
32768, 19168, 10548, 5568, 2865, 1454, 732,
367, 184, 92, 46, 23, 11, 5, 2
};
We determined these LUT values via a small Python script:
import math
print(", ".join(map(str, [int(math.log2(1 + math.pow(2, -i)) * (1 << 15)) for i in range(15)])))
Which outputted:
32768, 19168, 10548, 5568, 2865, 1454, 732, 367, 184, 92, 46, 23, 11, 5, 2
After this, our next big step was to implement Single Instruction Multiple Data (SIMD) via NEON. Our aim with this was to vectorize certain operations so that we could run them in parallel, opposed to strictly sequentially. Thankfully, upon checking the documentation, our Raspberry Pi's arm64 processor did have support for these kinds of operations! To be extra certain, I also connected to the Pi and inspected its cpuinfo file:
matthew@pi:~ $ cat /proc/cpuinfo | grep Features
This, as expected, listed out 4 processors, each with asimd capabilities. For some trivia, these are actually advanced SIMDs, hence their "a" prefix [6]:
Features : fp asimd evtstrm crc32 cpuid
Features : fp asimd evtstrm crc32 cpuid
Features : fp asimd evtstrm crc32 cpuid
Features : fp asimd evtstrm crc32 cpuid
To run NEON code, we also added the -march=armv8-a+simd flag to our gcc build and run command via our run.sh script. This instructed the compiler to use the ARMv8-A architecture with SIMD instructions enabled. However, after adding it we determined we didn't need to; with ARMv8-A, we implicitly have SIMD enabled.
After this initial preliminary investigation, we dug deeper into the iterative nature of the Convergence Computing Method, and realized parallelism might not be what we need — especially since our "add and shift"-type algorithm is iterative, where the th iteration relies on the th. It's clear that this is a bottleneck in the algorithm, being forced to await the previous iteration before completing the next. Further, Dr. Sima's CCM slides [4] showcased an "optimized solution, with rounding" that never included NEON at all! Thus, we almost decided to not use it. However, after I joined a Zoom call with Dr. Sima to clarify, he highlighted how I should use NEON for the lookup table specifically. After reading a lot of arm documentation and rewriting several times, I finally got the new NEON solution to compile!
I converted this, our original LUT:
int32_t LUT[K - 1] = {32768, 19168, 10548, 5568, 2865, 1454, 732, 367, 184, 92, 46, 23, 11, 5, 2};
Into:
// defining the LUT arrays separately
int32_t LUT_array1[4] = {32768, 19168, 10548, 5568};
int32_t LUT_array2[4] = {2865, 1454, 732, 367};
int32_t LUT_array3[4] = {184, 92, 46, 23};
// this last "-1" is a space filler, we don't need it
// we just want to fill up all 4 32-bit fields for alignment
int32_t LUT_array4[4] = {11, 5, 2, -1};
// loading LUT into NEON vectors
int32x4_t LUT_vec[4] = {
vld1q_s32(LUT_array1),
vld1q_s32(LUT_array2),
vld1q_s32(LUT_array3),
vld1q_s32(LUT_array4)
};
It's worth noting, we kept both the original LUT and the NEON-based LUT in the code temporarily for testing purposes.
The reason for converting from a fixed-array lookup table to a NEON vector was largely to take advantage of cache locality. This is because these new vectors are stored in single groups of contiguous memory, thus, when we access one, we're less likely to have to go out to main memory to get the next one. This definitely worked to speed up that bottleneck of having to calculate these lookup table values dynamically, as well as possibly cache-missing more frequently before having NEON.
The reason for us grouping our LUT values into 4 separate arrays was because our NEON vectors are 128-bits wide, so they could store 4 x 32-bit integers — the type of data we're working with.
Next, we decided to integrate a sweeping host of changes in an effort to improve the optimization and effectiveness of our function.
First, we introduced normalization to accept values larger than the theoretical range:
// at the start, we normalize
int shifts = 0;
while (M >= SCALE_FACTOR)
{
M >>= 1;
shifts++;
}
// later denormalizing after the main loop
f += shifts << 15; // K - 1 = 15
Next, we converted our previous version's loop from incrementing i by 1 each time, to 2. We figured using loop unrolling here would be smart as it would half the number of iterations required, and thus the number of loop header conditional checks.
Here's the initial header:
for (int i = 0; i < K - 1; i++) { ... }
Here's the improved one:
for (register int i = 0; i < K - 2; i += 2) { ... }
As you can see from this second loop above, we also introduced register keywords when needed. Doing so hints to the compiler that we want the following variable declaration to be stored in a register when possible, opposed to just memory. This tremendously helps the speed of accessing these variables and reduces the number of load/store operations required program-wide.
Further, we replaced the if/else statements inside the original provided unoptimized pseudocode from Dr. Sima with predicate operations. These are operations which directly set a variable based upon a condition opposed to needing to jump around conditionally. Thus, they're far more efficient.
Here is the new full loop:
for (register int i = 0; i < K - 2; i += 2)
{
// unrolled loop portion #1
register int32_t u1 = M + (M >> i);
register int32_t LUT_val1 = LUT[i];
register lteSF1 = u1 <= SCALE_FACTOR;
M = lteSF1 ? u1 : M;
f = lteSF1 ? f - LUT_val1 : f;
// unrolled loop portion #2
register int32_t u2 = M + (M >> (i+1));
register int32_t LUT_val2 = LUT[i + 1];
register lteSF2 = u2 <= SCALE_FACTOR;
M = (lteSF2) ? u2 : M;
f = (lteSF2) ? f - LUT_val2 : f;
}
As you can see, we also broke up the double "M and f setting conditional" into a single variable (lteSF1 and lteSF2 respectively for each unrolled portion). This allowed us to compute these values half as many times, creating a small speedup.
With this done, we decided to finally integrate our new NEON-based LUT table. Also, we decided to replace conditions like i < K - 2 with more bitwise-orientated code like !(i & 16) and operators with inefficient calls like / 2 we swapped to >> 1, leading to hopes of slightly improving performance [9, 10]. These optimizations took many different forms, including things like improving modulo efficiency with bitwise &s and adding software pipelining. After more experimenting, lots of compiling, and documentation reading, we finally achieved optimized code that looked as follows:
#include <stdio.h>
#include <stdint.h>
#include <arm_neon.h>
#define K 16
#define SCALE_FACTOR (1 << (K - 1))
int main()
{
// conversion to fixed-point notation
double real_input = 22;
register int32_t M = (int32_t)(real_input * SCALE_FACTOR);
register int32_t f = 0;
// defining the LUT arrays separately
int32_t LUT_array1[4] = {32768, 19168, 10548, 5568};
int32_t LUT_array2[4] = {2865, 1454, 732, 367};
int32_t LUT_array3[4] = {184, 92, 46, 23};
int32_t LUT_array4[4] = {11, 5, 2, -1}; // -1 to represent we don't use this place of the array, but have the space (for alignment)
// load the LUT into NEON vectors
int32x4_t LUT_vec[4] = {
vld1q_s32(LUT_array1),
vld1q_s32(LUT_array2),
vld1q_s32(LUT_array3),
vld1q_s32(LUT_array4)};
// normalization of M to range
int shifts = 0;
while (M >= SCALE_FACTOR)
{
M >>= 1;
shifts++;
}
for (register int i = 0; !(i & 16); i += 2)
{
// NEON to LUT value #1 for unroll 1
int32_t LUT_val1 = vgetq_lane_s32(LUT_vec[i >> 2], i & 3);
// #1 unrolled iter
register int32_t u1 = M + (M >> i);
register lteSF1 = u1 <= SCALE_FACTOR;
M = lteSF1 ? u1 : M;
f = lteSF1 ? f - LUT_val1 : f;
// pipelining!
// ...
// prepare for the next iteration within the current #2 one
if (!((i + 2) & 16))
{
// NEON to LUT value #2 for unroll 2
int32_t LUT_val2 = vgetq_lane_s32(LUT_vec[(i + 1) >> 2], (i + 1) & 3);
register int32_t u2 = M + (M >> (i + 1));
register lteSF2 = u2 <= SCALE_FACTOR;
M = lteSF2 ? u2 : M;
f = lteSF2 ? f - LUT_val2 : f;
}
}
// denormalize the fixed-point value
f += shifts << 15; // K - 1 = 15
printf("optimized fp ccm log2(%f) = %f
", 0.6, (double)f / SCALE_FACTOR);
return 0;
}
It's worth noting that we found the
registerkeywords did almost nothing. However, this was expected, as modern compilers are really good at optimizing CPU register usage. Thus, it likely ignored our explicit declarations.
Discussion🔗
Algorithm versions🔗
In short, we created 4 different custom versions of the algorithm, plus kept a baseline via the original default math-lib C implementation, log2.
Here are our versions:
1_base.c: The default Clog2function perfected over decades of work.2_unoptimized.c: Us transcribing Dr. Sima's pseudocode for the inefficient CCM solution.3_fixed_point_arithmetic.c: Adding fixed-point arithmetic to the previous implementation.4_defined_lut.c: Adding a defined non-dynamically generated lookup table to the previous implementation.5_general_optimizations: All other large optimizations.
Overall, here is everything our final version, 5_general_optimizations.c, utilized to improve performance:
- Operator strength reduction.
- Reducing function call overheads by putting everything into
main. - Using
registerkeywords to tell the compiler what we wanted kept in quick-access registers. - Locality of variable definitions.
- Bitwise operations. Things like:
/ 2->>> 1% 4->& 3- Loop conditions transforming to bitwise-based checks instead like
(!((i + 2) & 16)) - Etc.
- Software pipelining. This meant preloading the next iterations values so that we could have overlap in our calculations, improving speed.
- Predicate operations. This was aimed to improve branch mistraces.
- Loop unrolling. Specifically, we unrolled our loop twice.
- NEON SIMD for the lookup table to not waste the on-chip SIMD processing capabilities.
- Fixed-point arithmetic for increased precision across a lower range than floating point, albeit we used 32-bits to lower memory usage and because we figured we didn't need 64-bits of precision.
Running the code🔗
For the 5 versions we created, we ran the functions with logging such that the entire function wasn't optimized-away by our -O3 gcc flag. Further, we did not include any fixed-point conversion costs in our output and optimization calculations because we determined the client should deal with that (as Dr. Sima frequently said). This is because we figured if they're wanting this specific implementation of a algorithm created, they likely are already doing calculations in some fixed-point format, so adding that computational cost to our calculations would be situationally redundant.
Next, we had to decide which compiler flags to run our versions with. For our purposes, we desired not to use compiler optimizations for all versions except for the final optimization, 5_general_optimization.c.
Thus, here are the flag sets we ran each version with that specifically were there to aid with optimization [11]. We've excluded descriptions for brevity of the flags we already discussed earlier.
1_base.c,2_unoptimized.c,3_fixed_point_arithmetic.c, and4_defined_lut.c:- None.
5_general_optimizations:-mcpu=cortex-a72.-O3.-fno-stack-protector.-fomit-frame-pointer.-march=armv8-a: Specifies the architecture.-fprefetch-loop-arrays: Tells the compiler to pre-fetch data within loops when possible.-mtune=cortex-a72: Tells the compiler to tune the build for our one specific processor.-ftree-vectorize: Improves loop vectorization.-funroll-loops: Unrolls loops if possible.
We'd include a flag to enable NEON explicitly, but with our armV8-A architecture, it's enabled by default [12].
The assembly🔗
As mentioned earlier, we created a run.sh script, which, upon executing, utilized the -S flag to export the ran file's corresponding assembly code. This was then copied back to our local machine for inspection.
In Appendices A-E, we've included the assembly output for our 5 different versions of .
Further, in ARMv8-A, traditional predicate operations as seen in earlier ARM architectures are largely replaced by conditional branches and select instructions. The closest equivalent to predicate operations in ARMv8-A would be the use of the Conditional Select (csel, csinc, csinv, cset, etc.) instructions, which can be considered as performing operations based on a condition without branching.
We looked into explicitly optimizing the assembly instructions, but determined that wouldn't bring much improvement, as our final optimized version already had an extremely sparse ASM footprint.
Benchmarking🔗
For each version of the algorithm we ran, using Linux's perf, alongside the returned assembly files, we were able to gather great insight about program performance.
Here is a table to summarize:
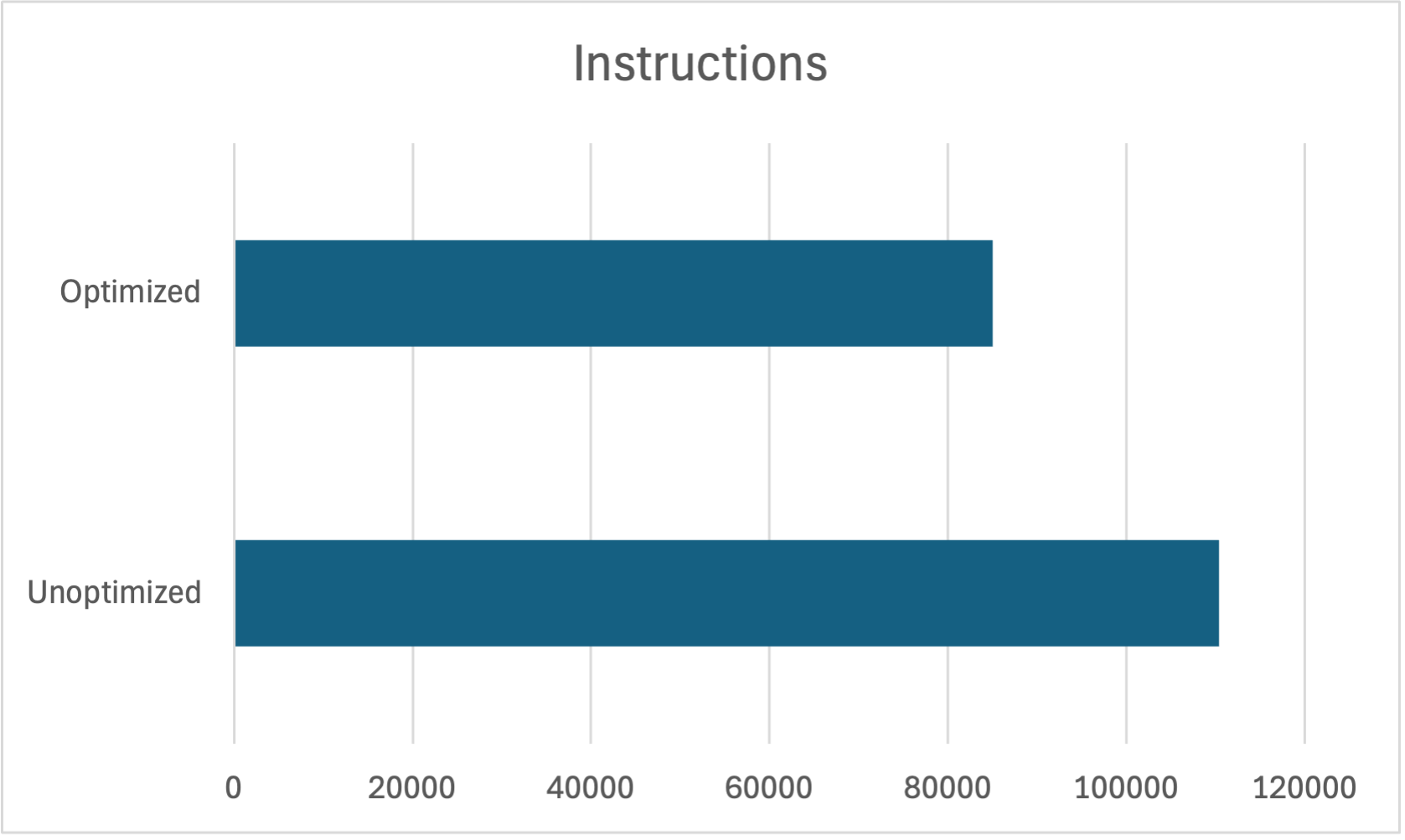
| Comparable versions | Version | Page faults | Cycles | Instructions | Branch misses | ASM file length |
|---|---|---|---|---|---|---|
| ❌ | 1_base.c (hyper-optimized library function) | 55 | 379,156 | 104,739 | 2,536 | 33 |
| Initial 🐢 | 2_unoptimized.c | 55 | 392,134 | 110,437 | 2,628 | 140 |
| ❌ | 3_fixed_point_arithmetic.c | 55 | 378,153 | 106,663 | 2,575 | 349 |
| ❌ | 4_defined_lut.c | 46 | 333,282 | 85,428 | 1,984 | 140 |
| Final 🐇 | 5_general_optimizations.c | 47 | 326,198 | 85,037 | 1,925 | 33 |
While this may look underwhelming, it's important to note ultimately we only care about comparing 2_unoptimized.c (unoptimized CCM pseudocode transcription) against 5_general_optimizations.c (final optimized version). This is especially paramount since we incrementally added features to each version, so some intermediary versions that look "better" statistically simply don't have the same feature sets.
Here some tables highlighting the key areas of improvement across the 2 algorithm versions that matter:
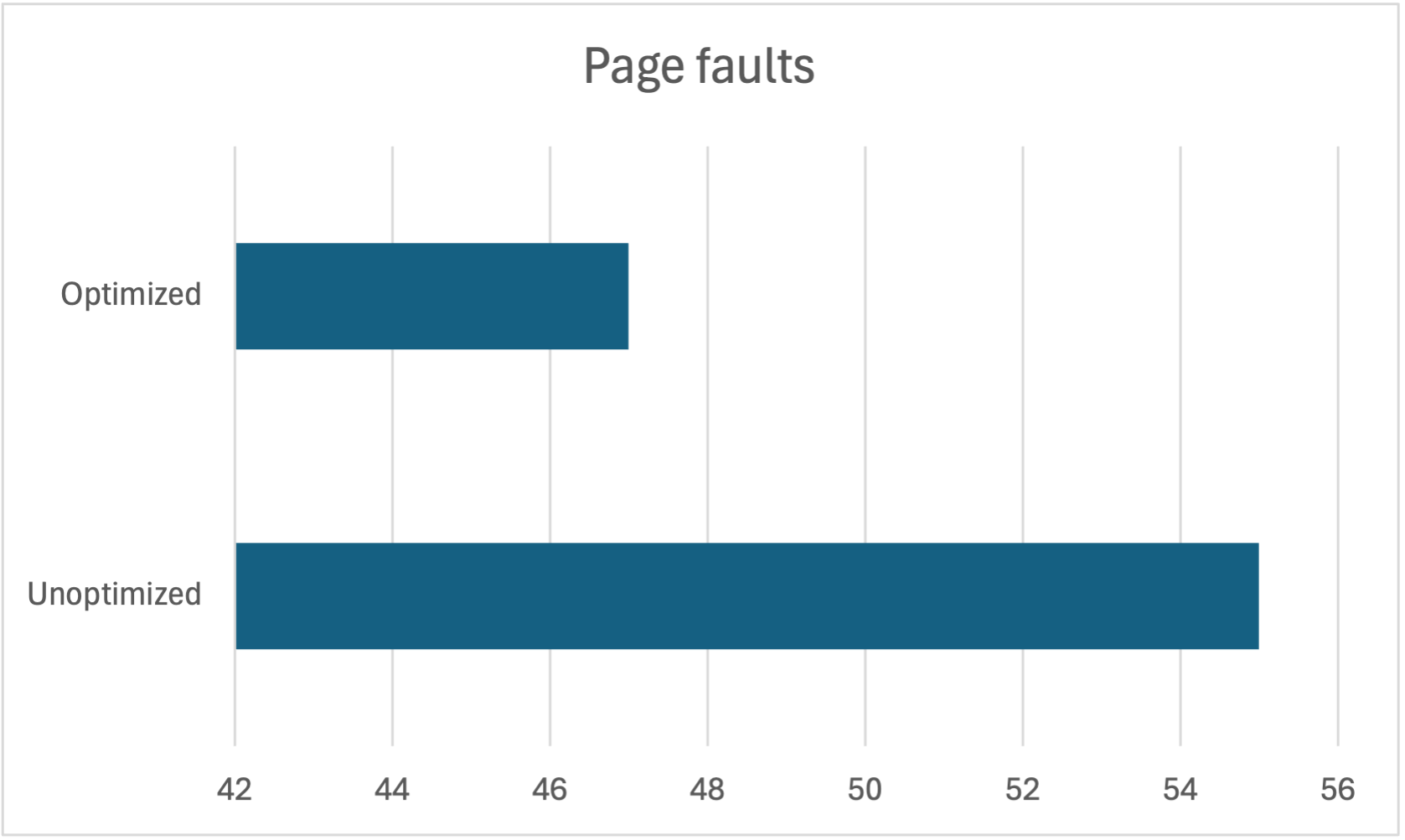
16% less page faults:
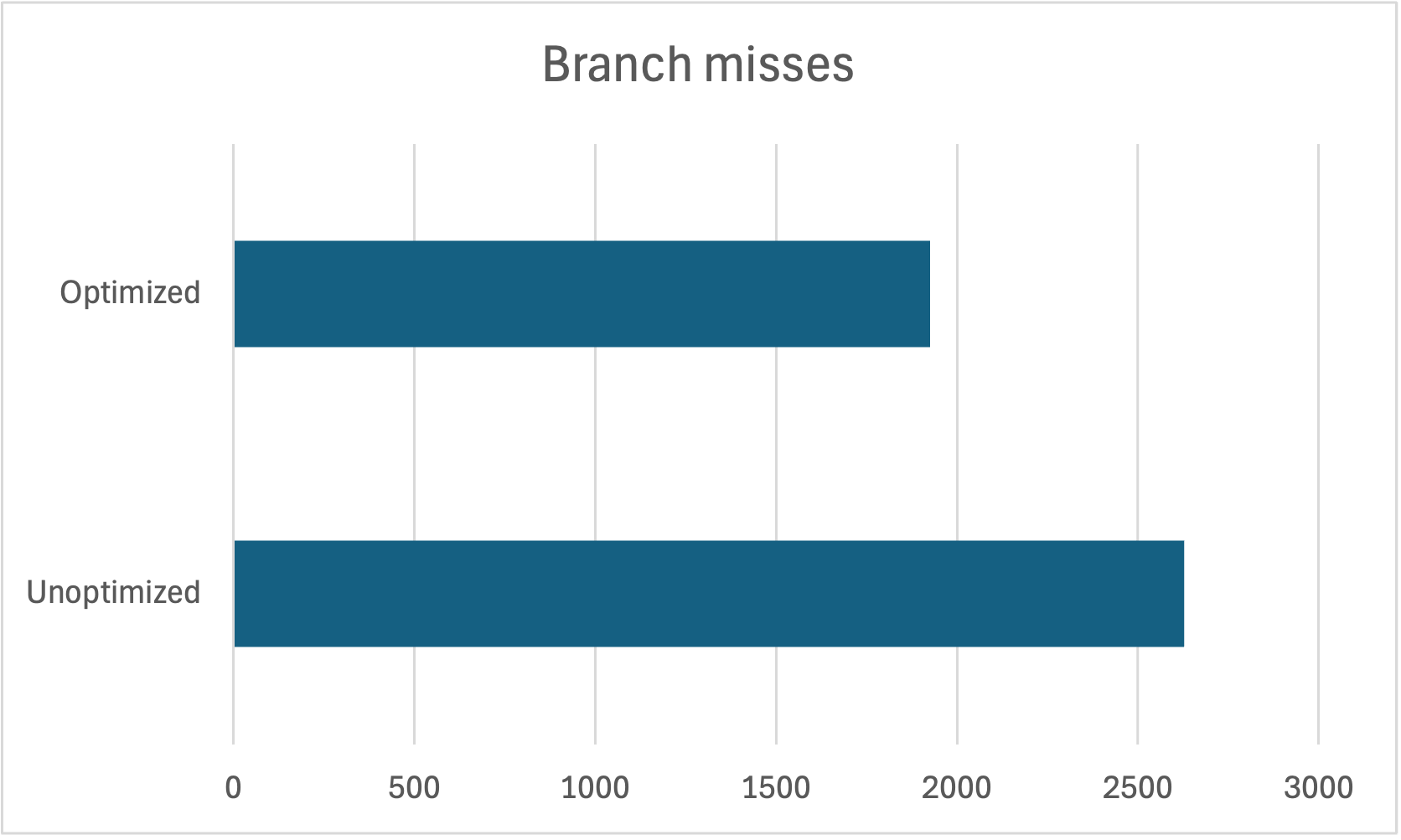
31% fewer branch misses:
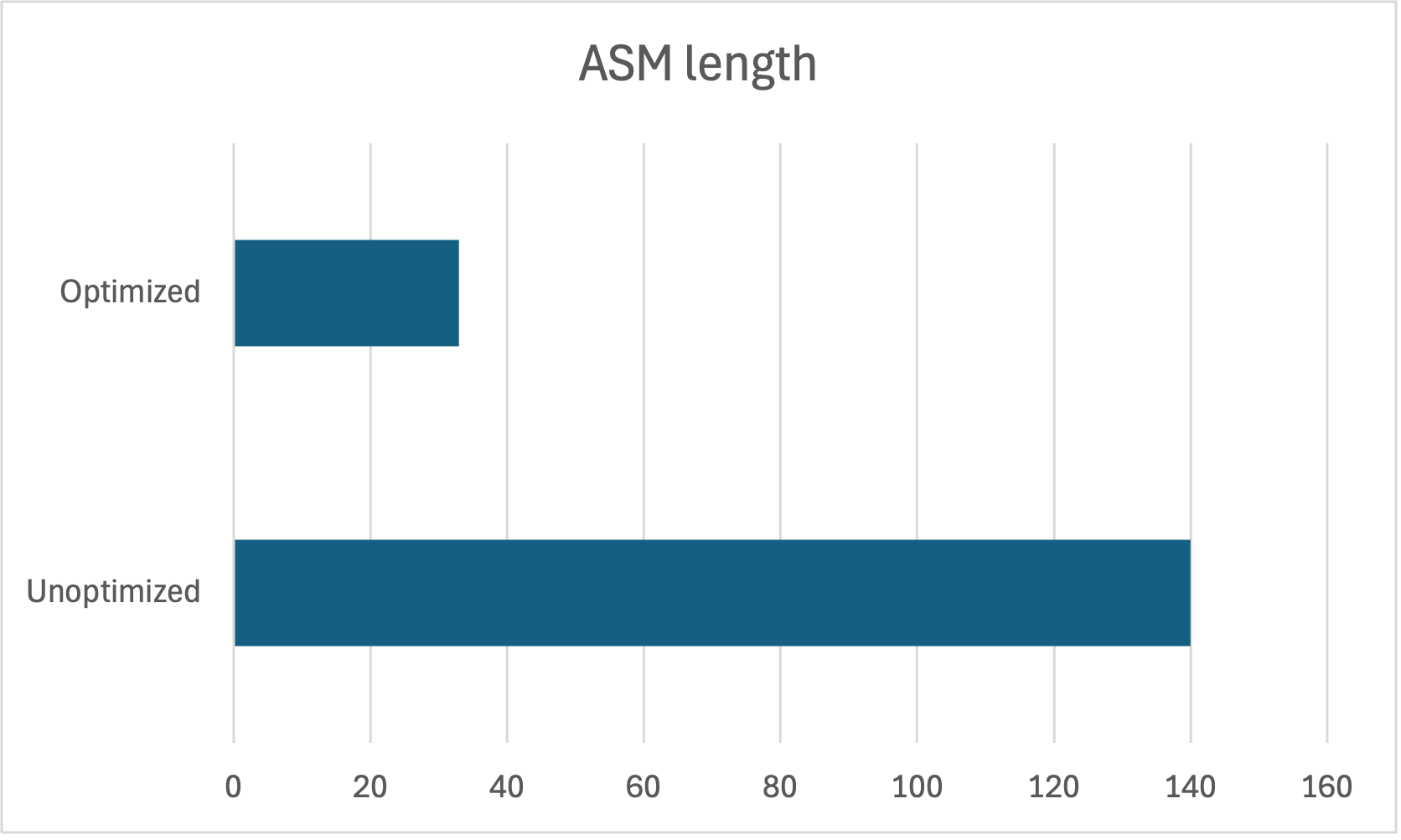
124% fewer lines of ASM:
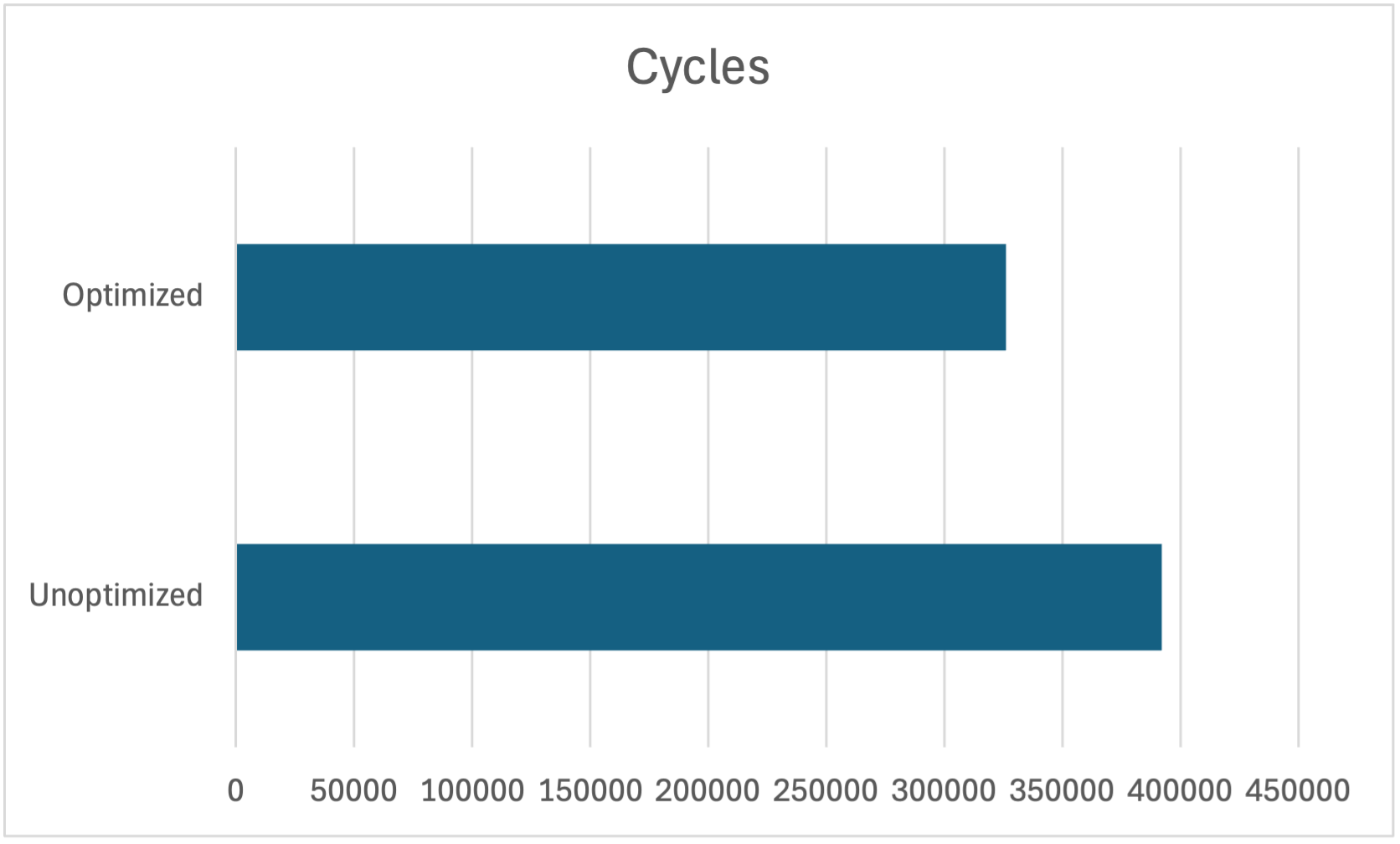
18% fewer cycles:
26% fewer instructions:
Correctness🔗
The optimized CCM algorithm (5_general_optimizations.c) maintained an accuracy and precision comparable to the baseline function. We ensured this was the case by creating a custom tester file, accuracy_tester.c, that fed 1,000 iterations of random inputs such that () into both our optimized algorithm and "true" function, <math.h> log2. In practice, any by some small epsilon would work given our normalization approach. We chose 100 as a max arbitrarily. In practice, is the max we could calculate before our function breaks. This, of course, is due to the bit length we chose.
Here's an excerpt of its output:
... ^ 998 more cases ^ ...
TEST CASE 999:
-----
Randomly chosen input: 34.719630
CCM log2: 5.117615
True log2: 5.117680
Percent difference: 0.001269%
TEST CASE 1000:
-----
Randomly chosen input: 53.251415
CCM log2: 5.734711
True log2: 5.734748
Percent difference: 0.000650%
MEAN OVERALL PERCENTAGE DIFFERENCE: 0.030550%
This % minor deviation is well within acceptable bounds for most applications, especially in contexts where performance is critical. Further, such variance was expected since we only utilized 32 of our possible 64-bits from our embedded system. This was a choice we made to improve memory usage and performance. Earlier we established using more bits increases precision.
Profiling🔗
We considered using Valgrind for our project, but ultimately decided against it for several reasons. The CCM algorithm we implemented is designed for quick execution and immediate termination, rather than being a long-running process. In this context, potential memory leaks would have minimal impact on performance or resource usage. Additionally, our implementation primarily uses static memory allocation and stack-based variables rather than heap-based, reducing the risk of memory-related issues that Valgrind typically identifies.
Similarly, we have also considered Cachegrind, but decided not to utilize it. While Cachegrind could potentially provide insights into cache behavior, our optimizations were primarily focused on algorithmic improvements and SIMD utilization rather than cache-level optimizations. The CCM implementation we developed uses a relatively small and fixed-size lookup table, which is loaded into NEON vector registers for efficient access. This approach already optimizes cache usage inherently.
Future work🔗
We have implemented and analyzed the CCM for , but it would be worthwhile to test an implementation similar to ours for other transcendental functions, like exponentials, square roots, or even cubic root functions.
Conclusion🔗
We opted against using Valgrind for our project because the CCM algorithm we implemented is designed for quick execution, with minimal concern for memory leaks due to its use of static memory allocation. Similarly, we chose not to use Cachegrind, as our focus was on algorithmic optimizations and SIMD utilization, rather than cache behavior.
References🔗
We wrote our references in a simple link format since no specific formatting style was required. We also included many additional external links embedded in the report itself for clarity.
- [1] https://en.wikipedia.org/wiki/Raspberry_Pi
- [2] https://pi.processing.org/technical/
- [3] https://www.quora.com/Which-instruction-set-architecture-is-used-in-Raspberry-Pi-4
- [4] Professor’s CCM slides
- [5] https://en.wikipedia.org/wiki/Integer_overflow
- [6] https://developer.arm.com/Architectures/Neon
- [7] https://stackoverflow.com/questions/10712972/what-is-the-use-of-fno-stack-protector
- [8] https://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer
- [9] https://stackoverflow.com/questions/20393373/performance-wise-how-fast-are-bitwise-operators-vs-normal-modulus
- [10] https://codedamn.com/news/c/bitwise-operators-in-c
- [11] https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
- [12] https://gcc.gnu.org/onlinedocs/gcc/ARM-Options.html
- [13] https://en.wikipedia.org/wiki/Floating-point_unit
Appendices🔗
Appendix A🔗
1_base.s ASM file.
.arch armv8-a
.file "1_base.c"
.text
.section .rodata.str1.8,"aMS",@progbits,1
.align 3
.LC0:
.string "base log2(%f) = %f
"
.section .text.startup,"ax",@progbits
.align 2
.p2align 4,,15
.global main
.type main, %function
main:
.LFB11:
.cfi_startproc
adrp x0, .LC0
movi d1, #0
fmov d0, 1.0e+0
add x0, x0, :lo12:.LC0
str x30, [sp, -16]!
.cfi_def_cfa_offset 16
.cfi_offset 30, -16
bl printf
ldr x30, [sp], 16
.cfi_restore 30
.cfi_def_cfa_offset 0
mov w0, 0
ret
.cfi_endproc
.LFE11:
.size main, .-main
.ident "GCC: (Debian 12.2.0-14) 12.2.0"
.section .note.GNU-stack,"",@progbits
Appendix B🔗
2_unoptimized.s ASM file.
.arch armv8-a
.file "2_unoptimized.c"
.text
.align 2
.global calculate_lut
.type calculate_lut, %function
calculate_lut:
.LFB0:
.cfi_startproc
stp x29, x30, [sp, -64]!
.cfi_def_cfa_offset 64
.cfi_offset 29, -64
.cfi_offset 30, -56
mov x29, sp
str x19, [sp, 16]
.cfi_offset 19, -48
str x0, [sp, 40]
str wzr, [sp, 60]
b .L2
.L3:
ldr w0, [sp, 60]
neg w0, w0
scvtf d0, w0
fmov d1, d0
fmov d0, 2.0e+0
bl pow
fmov d1, d0
fmov d0, 1.0e+0
fadd d0, d1, d0
ldrsw x0, [sp, 60]
lsl x0, x0, 3
ldr x1, [sp, 40]
add x19, x1, x0
bl log2
str d0, [x19]
ldr w0, [sp, 60]
add w0, w0, 1
str w0, [sp, 60]
.L2:
ldr w0, [sp, 60]
cmp w0, 14
ble .L3
nop
nop
ldr x19, [sp, 16]
ldp x29, x30, [sp], 64
.cfi_restore 30
.cfi_restore 29
.cfi_restore 19
.cfi_def_cfa_offset 0
ret
.cfi_endproc
.LFE0:
.size calculate_lut, .-calculate_lut
.align 2
.global log2_CCM
.type log2_CCM, %function
log2_CCM:
.LFB1:
.cfi_startproc
stp x29, x30, [sp, -192]!
.cfi_def_cfa_offset 192
.cfi_offset 29, -192
.cfi_offset 30, -184
mov x29, sp
str d0, [sp, 24]
add x0, sp, 32
bl calculate_lut
str xzr, [sp, 184]
str wzr, [sp, 180]
b .L5
.L8:
ldr w0, [sp, 180]
neg w0, w0
scvtf d0, w0
fmov d1, d0
fmov d0, 2.0e+0
bl pow
fmov d1, d0
fmov d0, 1.0e+0
fadd d0, d1, d0
ldr d1, [sp, 24]
fmul d0, d1, d0
str d0, [sp, 168]
ldrsw x0, [sp, 180]
lsl x0, x0, 3
add x1, sp, 32
ldr d0, [x1, x0]
ldr d1, [sp, 184]
fsub d0, d1, d0
str d0, [sp, 160]
ldr d1, [sp, 168]
fmov d0, 1.0e+0
fcmpe d1, d0
bls .L10
b .L6
.L10:
ldr d0, [sp, 168]
str d0, [sp, 24]
ldr d0, [sp, 160]
str d0, [sp, 184]
.L6:
ldr w0, [sp, 180]
add w0, w0, 1
str w0, [sp, 180]
.L5:
ldr w0, [sp, 180]
cmp w0, 14
ble .L8
ldr d0, [sp, 184]
ldp x29, x30, [sp], 192
.cfi_restore 30
.cfi_restore 29
.cfi_def_cfa_offset 0
ret
.cfi_endproc
.LFE1:
.size log2_CCM, .-log2_CCM
.align 2
.global main
.type main, %function
main:
.LFB2:
.cfi_startproc
sub sp, sp, #16
.cfi_def_cfa_offset 16
mov x0, 3689348814741910323
movk x0, 0x3fe3, lsl 48
fmov d0, x0
str d0, [sp, 8]
mov w0, 0
add sp, sp, 16
.cfi_def_cfa_offset 0
ret
.cfi_endproc
.LFE2:
.size main, .-main
.ident "GCC: (Debian 12.2.0-14) 12.2.0"
.section .note.GNU-stack,"",@progbits
Appendix C🔗
3_fixed_point_arithmetic.s ASM file.
.arch armv8-a
.file "3_fixed_point_arithmetic.c"
.text
.align 2
.p2align 4,,15
.global calculate_lut
.type calculate_lut, %function
calculate_lut:
.LFB11:
.cfi_startproc
mov x1, 4674736413210574848
stp x19, x20, [sp, -80]!
.cfi_def_cfa_offset 80
.cfi_offset 19, -80
.cfi_offset 20, -72
mov x20, x0
mov x19, 0
stp d8, d9, [sp, 64]
.cfi_offset 72, -16
.cfi_offset 73, -8
fmov d9, 1.0e+0
fmov d8, x1
stp x21, x22, [sp, 16]
stp x23, x24, [sp, 32]
str x30, [sp, 48]
.cfi_offset 21, -64
.cfi_offset 22, -56
.cfi_offset 23, -48
.cfi_offset 24, -40
.cfi_offset 30, -32
.L2:
neg w0, w19
fmov d0, 2.0e+0
add x21, x19, 1
add x23, x19, 3
add x24, x19, 2
scvtf d1, w0
add x22, x19, 4
bl pow
fadd d0, d0, d9
bl log2
fmov d2, d0
mvn w2, w19
fmov d0, 2.0e+0
scvtf d1, w2
fmul d3, d2, d8
fcvtzs w3, d3
str w3, [x20, x19, lsl 2]
add x19, x19, 5
bl pow
fadd d0, d0, d9
bl log2
fmov d4, d0
mvn w4, w21
fmov d0, 2.0e+0
scvtf d1, w4
fmul d5, d4, d8
fcvtzs w5, d5
str w5, [x20, x21, lsl 2]
bl pow
fadd d0, d0, d9
bl log2
fmov d6, d0
neg w6, w23
fmov d0, 2.0e+0
scvtf d1, w6
fmul d7, d6, d8
fcvtzs w7, d7
str w7, [x20, x24, lsl 2]
bl pow
fadd d0, d0, d9
bl log2
fmov d16, d0
neg w8, w22
fmov d0, 2.0e+0
scvtf d1, w8
fmul d17, d16, d8
fcvtzs w9, d17
str w9, [x20, x23, lsl 2]
bl pow
fadd d0, d0, d9
bl log2
fmul d0, d0, d8
cmp x19, 15
fcvtzs w10, d0
str w10, [x20, x22, lsl 2]
bne .L2
ldp x21, x22, [sp, 16]
ldp x23, x24, [sp, 32]
ldr x30, [sp, 48]
ldp d8, d9, [sp, 64]
ldp x19, x20, [sp], 80
.cfi_restore 20
.cfi_restore 19
.cfi_restore 30
.cfi_restore 23
.cfi_restore 24
.cfi_restore 21
.cfi_restore 22
.cfi_restore 72
.cfi_restore 73
.cfi_def_cfa_offset 0
ret
.cfi_endproc
.LFE11:
.size calculate_lut, .-calculate_lut
.align 2
.p2align 4,,15
.global log2_CCM
.type log2_CCM, %function
log2_CCM:
.LFB12:
.cfi_startproc
mov x1, 4674736413210574848
stp x19, x20, [sp, -160]!
.cfi_def_cfa_offset 160
.cfi_offset 19, -160
.cfi_offset 20, -152
mov x20, 1
mov w19, w0
stp d8, d9, [sp, 80]
.cfi_offset 72, -80
.cfi_offset 73, -72
fmov d9, 1.0e+0
fmov d8, x1
stp x21, x22, [sp, 16]
.cfi_offset 21, -144
.cfi_offset 22, -136
add x22, sp, 96
stp x23, x24, [sp, 32]
.cfi_offset 23, -128
.cfi_offset 24, -120
mov w23, w20
stp x25, x26, [sp, 48]
str x30, [sp, 64]
.cfi_offset 25, -112
.cfi_offset 26, -104
.cfi_offset 30, -96
.L11:
sub w0, w23, w20
fmov d0, 2.0e+0
add x21, x20, 1
add x26, x20, 2
add x25, x20, 3
scvtf d1, w0
add x24, x20, 4
bl pow
fadd d0, d0, d9
bl log2
fmov d2, d0
sub w3, w23, w21
add x2, x22, x20, lsl 2
fmov d0, 2.0e+0
add x21, x22, x21, lsl 2
add x20, x20, 5
scvtf d1, w3
fmul d3, d2, d8
fcvtzs w4, d3
str w4, [x2, -4]
bl pow
fadd d0, d0, d9
bl log2
fmov d4, d0
sub w5, w23, w26
fmov d0, 2.0e+0
add x26, x22, x26, lsl 2
scvtf d1, w5
fmul d5, d4, d8
fcvtzs w6, d5
str w6, [x21, -4]
bl pow
fadd d0, d0, d9
bl log2
fmov d6, d0
sub w7, w23, w25
fmov d0, 2.0e+0
add x25, x22, x25, lsl 2
scvtf d1, w7
fmul d7, d6, d8
fcvtzs w8, d7
str w8, [x26, -4]
bl pow
fadd d0, d0, d9
bl log2
fmov d16, d0
sub w9, w23, w24
fmov d0, 2.0e+0
add x24, x22, x24, lsl 2
scvtf d1, w9
fmul d17, d16, d8
fcvtzs w10, d17
str w10, [x25, -4]
bl pow
fadd d0, d0, d9
bl log2
fmul d0, d0, d8
cmp x20, 16
fcvtzs w11, d0
str w11, [x24, -4]
bne .L11
lsl w12, w19, 1
ldr w13, [sp, 96]
mov w1, 0
cmp w12, 32768
bgt .L12
neg w1, w13
mov w19, w12
.L12:
add w14, w19, w19, asr 1
ldr w15, [sp, 100]
cmp w14, 32768
bgt .L13
sub w1, w1, w15
mov w19, w14
.L13:
add w16, w19, w19, asr 2
ldr w17, [sp, 104]
cmp w16, 32768
bgt .L14
sub w1, w1, w17
mov w19, w16
.L14:
add w18, w19, w19, asr 3
ldr w30, [sp, 108]
cmp w18, 32768
bgt .L15
sub w1, w1, w30
mov w19, w18
.L15:
add w23, w19, w19, asr 4
ldr w22, [sp, 112]
cmp w23, 32768
bgt .L16
sub w1, w1, w22
mov w19, w23
.L16:
add w0, w19, w19, asr 5
ldr w2, [sp, 116]
cmp w0, 32768
bgt .L17
sub w1, w1, w2
mov w19, w0
.L17:
add w3, w19, w19, asr 6
ldr w20, [sp, 120]
cmp w3, 32768
bgt .L18
sub w1, w1, w20
mov w19, w3
.L18:
add w4, w19, w19, asr 7
ldr w21, [sp, 124]
cmp w4, 32768
bgt .L19
sub w1, w1, w21
mov w19, w4
.L19:
add w5, w19, w19, asr 8
ldr w6, [sp, 128]
cmp w5, 32768
bgt .L20
sub w1, w1, w6
mov w19, w5
.L20:
add w26, w19, w19, asr 9
ldr w7, [sp, 132]
cmp w26, 32768
bgt .L21
sub w1, w1, w7
mov w19, w26
.L21:
add w8, w19, w19, asr 10
ldr w25, [sp, 136]
cmp w8, 32768
bgt .L22
sub w1, w1, w25
mov w19, w8
.L22:
add w9, w19, w19, asr 11
ldr w10, [sp, 140]
cmp w9, 32768
bgt .L23
sub w1, w1, w10
mov w19, w9
.L23:
add w24, w19, w19, asr 12
ldr w11, [sp, 144]
cmp w24, 32768
bgt .L24
sub w1, w1, w11
mov w19, w24
.L24:
add w12, w19, w19, asr 13
ldr w13, [sp, 148]
cmp w12, 32768
bgt .L25
sub w1, w1, w13
mov w19, w12
.L25:
ldr w15, [sp, 152]
add w14, w19, w19, asr 14
ldp x21, x22, [sp, 16]
cmp w14, 32768
ldp x23, x24, [sp, 32]
sub w16, w1, w15
csel w0, w16, w1, le
ldp x25, x26, [sp, 48]
ldr x30, [sp, 64]
ldp d8, d9, [sp, 80]
ldp x19, x20, [sp], 160
.cfi_restore 20
.cfi_restore 19
.cfi_restore 30
.cfi_restore 25
.cfi_restore 26
.cfi_restore 23
.cfi_restore 24
.cfi_restore 21
.cfi_restore 22
.cfi_restore 72
.cfi_restore 73
.cfi_def_cfa_offset 0
ret
.cfi_endproc
.LFE12:
.size log2_CCM, .-log2_CCM
.section .text.startup,"ax",@progbits
.align 2
.p2align 4,,15
.global main
.type main, %function
main:
.LFB13:
.cfi_startproc
mov w0, 19660
str x30, [sp, -16]!
.cfi_def_cfa_offset 16
.cfi_offset 30, -16
bl log2_CCM
ldr x30, [sp], 16
.cfi_restore 30
.cfi_def_cfa_offset 0
mov w0, 0
ret
.cfi_endproc
.LFE13:
.size main, .-main
.ident "GCC: (Debian 12.2.0-14) 12.2.0"
.section .note.GNU-stack,"",@progbits
Appendix D🔗
4_defined_lut.s ASM file.
.arch armv8-a
.file "4_defined_lut.c"
.text
.align 2
.p2align 4,,15
.global log2_CCM
.type log2_CCM, %function
log2_CCM:
.LFB11:
.cfi_startproc
lsl w1, w0, 1
mov w2, -32768
cmp w1, 32768
csel w1, w0, w1, gt
add w3, w1, w1, asr 1
csel w0, wzr, w2, gt
cmp w3, 32768
bgt .L3
mov w4, -19168
mov w1, w3
add w0, w0, w4
.L3:
add w5, w1, w1, asr 2
cmp w5, 32768
bgt .L4
mov w6, -10548
mov w1, w5
add w0, w0, w6
.L4:
add w7, w1, w1, asr 3
cmp w7, 32768
bgt .L5
mov w8, -5568
mov w1, w7
add w0, w0, w8
.L5:
add w9, w1, w1, asr 4
cmp w9, 32768
bgt .L6
sub w0, w0, #2865
mov w1, w9
.L6:
add w10, w1, w1, asr 5
cmp w10, 32768
bgt .L7
sub w0, w0, #1454
mov w1, w10
.L7:
add w11, w1, w1, asr 6
cmp w11, 32768
bgt .L8
sub w0, w0, #732
mov w1, w11
.L8:
add w12, w1, w1, asr 7
cmp w12, 32768
bgt .L9
sub w0, w0, #367
mov w1, w12
.L9:
add w13, w1, w1, asr 8
cmp w13, 32768
bgt .L10
sub w0, w0, #184
mov w1, w13
.L10:
add w14, w1, w1, asr 9
cmp w14, 32768
bgt .L11
sub w0, w0, #92
mov w1, w14
.L11:
add w15, w1, w1, asr 10
cmp w15, 32768
bgt .L12
sub w0, w0, #46
mov w1, w15
.L12:
add w16, w1, w1, asr 11
cmp w16, 32768
bgt .L13
sub w0, w0, #23
mov w1, w16
.L13:
add w17, w1, w1, asr 12
cmp w17, 32768
bgt .L14
sub w0, w0, #11
mov w1, w17
.L14:
add w18, w1, w1, asr 13
cmp w18, 32768
bgt .L15
sub w0, w0, #5
mov w1, w18
.L15:
add w3, w1, w1, asr 14
sub w2, w0, #2
cmp w3, 32768
csel w0, w2, w0, le
ret
.cfi_endproc
.LFE11:
.size log2_CCM, .-log2_CCM
.section .text.startup,"ax",@progbits
.align 2
.p2align 4,,15
.global main
.type main, %function
main:
.LFB12:
.cfi_startproc
mov w0, 0
ret
.cfi_endproc
.LFE12:
.size main, .-main
.global LUT
.section .rodata
.align 4
.type LUT, %object
.size LUT, 60
LUT:
.word 32768
.word 19168
.word 10548
.word 5568
.word 2865
.word 1454
.word 732
.word 367
.word 184
.word 92
.word 46
.word 23
.word 11
.word 5
.word 2
.ident "GCC: (Debian 12.2.0-14) 12.2.0"
.section .note.GNU-stack,"",@progbits
Appendix E🔗
5_general_optimizations.s ASM file.
.arch armv8-a
.file "5_general_optimizations.c"
.text
.section .rodata.str1.8,"aMS",@progbits,1
.align 3
.LC0:
.string "ccm log2(%d) = %d
"
.section .text.startup,"ax",@progbits
.align 2
.p2align 4,,15
.global main
.type main, %function
main:
.LFB4361:
.cfi_startproc
adrp x0, .LC0
mov w2, -24148
str x30, [sp, -16]!
.cfi_def_cfa_offset 16
.cfi_offset 30, -16
mov w1, 19660
add x0, x0, :lo12:.LC0
bl printf
ldr x30, [sp], 16
.cfi_restore 30
.cfi_def_cfa_offset 0
mov w0, 0
ret
.cfi_endproc
.LFE4361:
.size main, .-main
.ident "GCC: (Debian 12.2.0-14) 12.2.0"
.section .note.GNU-stack,"",@progbits